Foundations for Speech Foundation Models
A summary of our recent work at WAVLab towards building large-scale speech foundation models
Introduction
The explosion in generative AI has taken the world by storm: powerful pretrained models like GPT-4 and Stable Diffusion have already entered the mainstream media and consumer pockets. While the trend towards large-scale models is no different in speech, a concensus has yet to be seen on what techniques will drive the speech foundation models of tomorrow. To help enable this progress, we are very excited to share the techniques and resources we have been developing at WAVLab, many of which will be publicly released for both academic and commerical use in the coming weeks. This blog will talk about four works in particular:
- YODAS: An open-source multilingual dataset with over 420k hours of annotated data
- OWSM: A transparent reproduction of OpenAI’s Whisper from scratch
- WavLabLM: Joint denoising for cross-lingual speech representation learning
- ML-SUPERB Challenge: A community driven speech benchmark for 154 languages
If you’re reading this in 2023, these works will be presented at ASRU. Come visit our presentations in Taipei if you are interested in more details! Be sure to check out the Colab demos for OWSM and WavLabLM linked below too.
YODAS: 420k Hours of Annotated Multilingual Data
Authors
Xinjian Li, Shinnosuke Takamichi, Takaaki Saeki, William Chen, Sayaka Shiota, Shinji Watanabe
Paper and Data coming soon
Unlike text-driven Large Language Models, many spoken language tasks are inherently multi-modal: we often interact with these speech models through text, either as an input or output. This makes paired speech-text data a neccessity, but it is much more difficult to acquire compared to unpaired speech or unpaired text. Companies like Google and Meta are able to train large-scale speech foundation models
Our answer is YODAS, a Youtube-Oriented Dataset for Audio and Speech that consists of over 500k hours of speech data across 140 languages, with 420k hours of the data having paired textual transcripts. To create YODAS, we extensively crawled Youtube for about half a year, collecting both audio data and the provided transcriptions. These transcriptions however, are not synced with the speech. We need to first align each sentence in the transcript to timestamps in the audio, after which we can segment the audio into smaller clips. Without this step, the audio would be too long and not fit into the GPU for model training.
To perform the segmentation, we used a pre-trained acoustic model
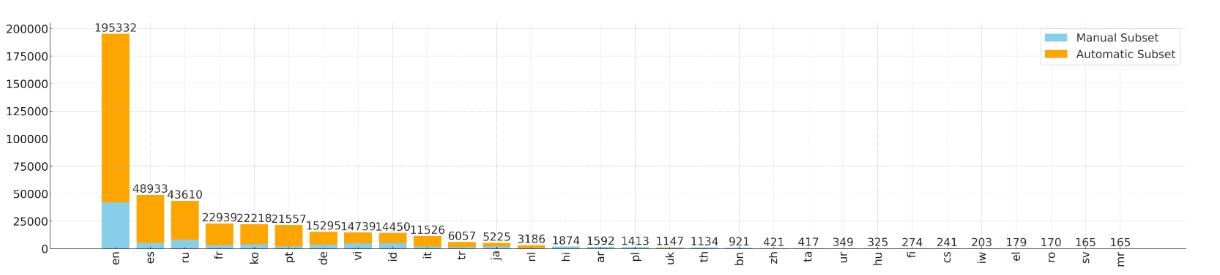
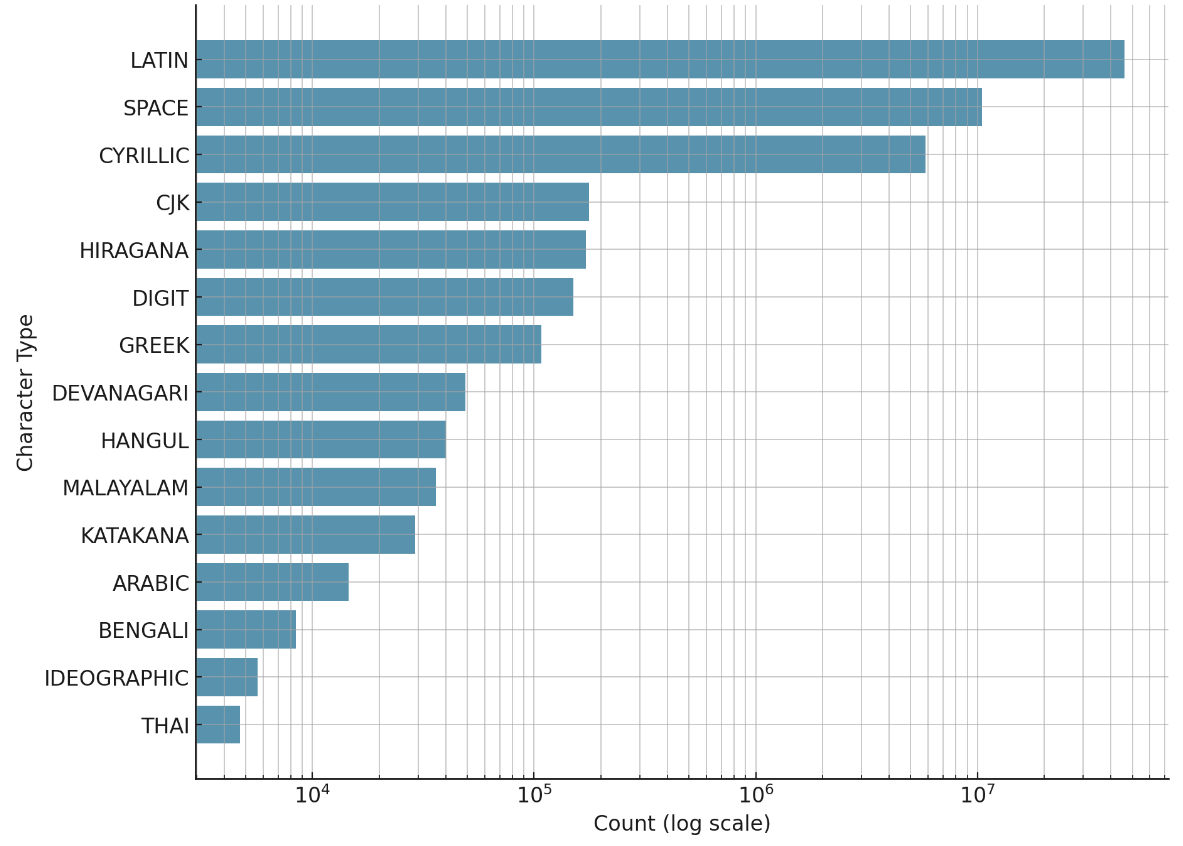
Most importantly, we only crawled videos released with a Creative Commons 3.0 License, meaning all of our data can be made open-source and even used commerically! We plan to release the data over HuggingFace Datasets in the next months, so stay tuned! If you’re interested in more details about our crawling method or data distribution, the paper will also be released on arXiv soon.
OWSM: Understanding Large-scale Weak Supervision
Authors
Yifan Peng, Jinchuan Tian, Brian Yan, Dan Berrebbi, Xuankai Chang, Xinjian Li, Jiatong Shi, Siddhant Arora, William Chen, Roshan Sharma, Wangyou Zhang, Yui Sudo, Muhammad Shakeel, Jee-weon Jung, Soumi Maiti, Shinji Watanabe
| Model | Paper | Code | Demo |
While the attention of speech researchers has been mostly occupied by self-supervised BERT-style models in the past several years, the introduction of Whisper
But using such large-scale proprietary models for research is risky. As the scale of AI models grow, the chance of data corruption only gets higher. How can researchers understand the capabilites of these models without knowing the data they are trained on? Our goal is to produce a model with the capabilities of Whisper, but with full transparency on the training data. We are excited to share our first steps towards this direction: OWSM (Open Whisper-style Speech Model, pronounced “Awesome!”).
Similar to Whisper, OWSM is a Transformer encoder-decoder trained on 30 second segments of paired speech/text data. The model is trained to perform multiple tasks, such as ASR, language identification, speech translation, and timestamp prediction. However, there are also a few key differences. OWSM downsamples the input by 4 times instead of 2 times, for better training efficiency. We also employ an auxilliary CTC loss, which stabilizes training. It allows OWSM to perform joint CTC/attention decoding, which helps prevents repeated tokens and makes inference parameters easier to tune. Finally, OWSM supports any-to-any speech translation, while Whisper can only perform any-to-English.
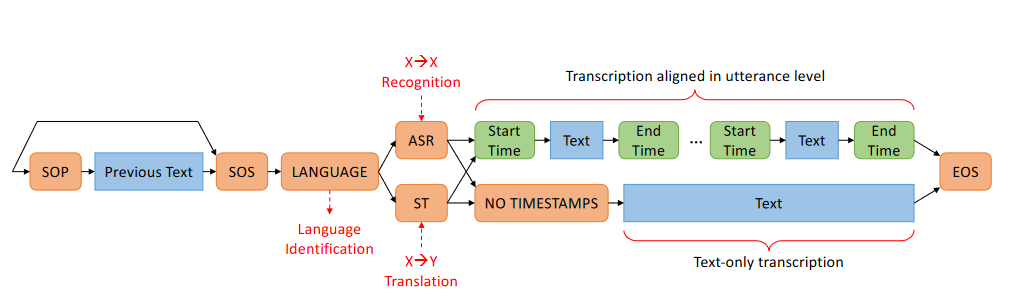
OWSM is trained exclusively on publicly accessible datasets, which totals to over 180k hours of speech, roughly a quarter to that of Whisper’s 680k. This makes OWSM by far the largest speech model trained by an academic group, and rivals many proposed by industrial research labs. Training the final version of OWSM took 10 days on 64 A100 40GB GPUs, or about 15,400 GPU hours. Counting our abalations and scaling experiments, we consumed around 36,000 total GPU hours, or about half of our computational budget for the whole year! We will be working to scale OWSM to 1 million hours of data. So if you want collaborate/sponsor the next generation of spoken language models, don’t hesitate to reach out!
WavLabLM: Multilingual Self-Supervised Speech Representations
Authors
William Chen, Jiatong Shi, Brian Yan, Dan Berrebbi, Wangyou Zhang, Yifan Peng, Xuankai Chang, Soumi Maiti, Shinji Watanabe
| Model | Paper | Code coming soon | Demo |
Supervised models like OWSM and Whisper have impressive few-shot or zero-shot capabilities, but they still rely upon paired speech/text data, which always be more expensive to obtain than unlabeled speech. Thus from a practical standpoint, pure self-supervised learning is still necessary to extend speech technologies to more universal applications, such as speech processing for more languages. Encoders such as WavLM
Of course, there has been a plethora of existing work on multilingual self-supervised speech models. XLS-R 53, XLSR-128, and MMS
WavLabLM is built on the discrete masked-prediction technique proposed by HuBERT. We first extract self-supervised representations from the unlabeled speech using a HuBERT model, which are then quantized into discrete units via k-means clustering. Random portions of the input speech is masked and fed into WavLabLM, which must predict the corresponding discrete units of the masked speech using the information in the unmasked speech. Furthermore, the input speech is augmented by random distractors the model must avoid. In every training step, we randomly sample another utterance or some random noise to mix into the actual input. This is the denoising portion of the pre-training approach, allowing the model to become more robust to noise and not overfit to clean single-speaker speech.
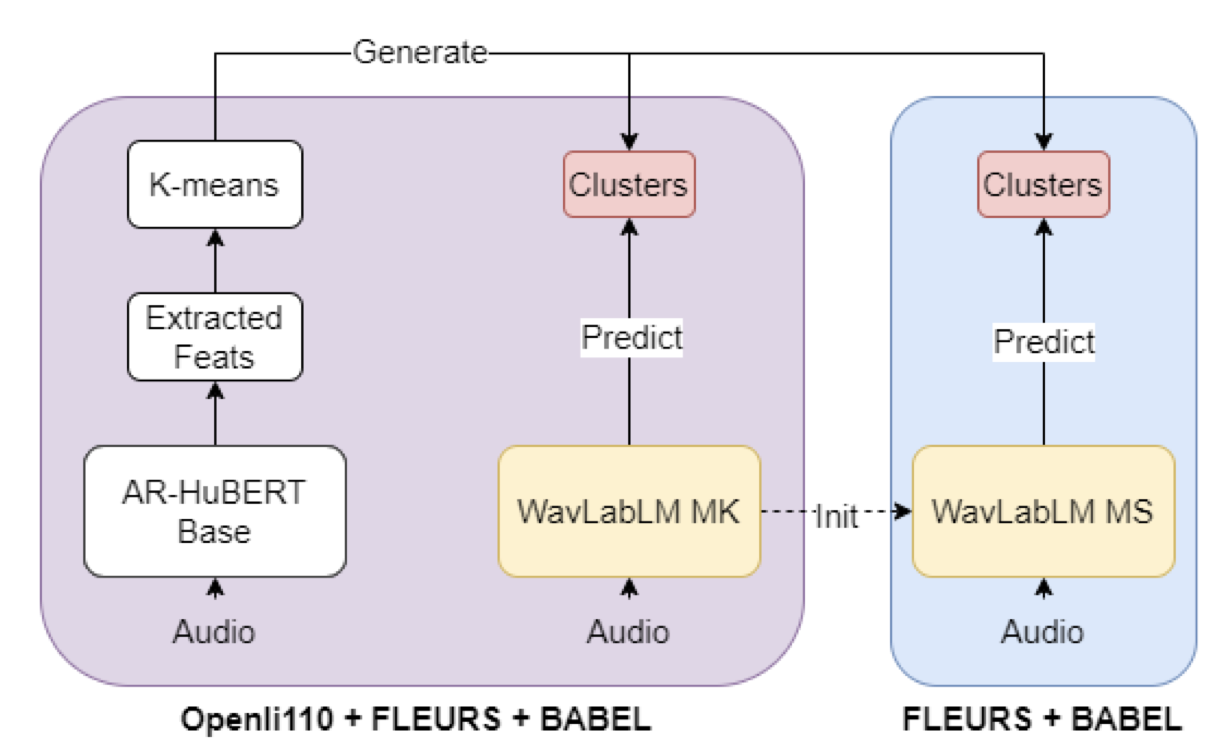
During this process, we found that multilingual pre-training introduces new complications. One of the most important is the language imbalance of the data. Low-resource languages, which consist of a smaller portion of the dataset, are seen less often during pre-training. This leads to degraded downstream performance and dampens the cross-lingual transfer learning capabilities of the model. A popular approach is to upsample low-resource languages, but that may require significant amounts of tuning and thus spending compute we do not have. We instead propose a simple multi-stage approach. We first pre-train WavLabLM on the full unbalanced dataset, and then further pre-train it for only a few steps on a balanced subset. This proved to be important in improving performance on the ML-SUPERB Benchmark, particularly in tasks involving languages other than those from West Europe or East Asia.
The ML-SUPERB Challenge: Community-Driven Benchmarking for over 150 Languages
Authors
Jiatong Shi, William Chen, Dan Berrebbi, Hsiu-Hsuan Wang, Wei-Ping Huang, En-Pei Hu, Ho-Lam Chuang, Xuankai Chang, Yuxun Tang, Shang-Wen Li, Abdelrahman Mohamed, Hung-yi Lee, Shinji Watanabe
Speech enjoys a variety of self-supervised models, all of which use different types of architectures or pre-training tasks. But how do you know which models are the best for a given task? Traditionally, the SUPERB Benchmark has been the go-to resource for answering this question. It tests the ability of these models across various speech processing tasks, ranging from speaker identification to speech recognition. However, all of the tasks in SUPERB are in English. So while it can answer the aforementioned question well, another one remains open: What are the best models for a given language? We sought to answer this question when we developed the Multilingual SUPERB (ML-SUPERB) Benchmark
ML-SUPERB benchmarks self-supervised models on speech recognition for 143 languages. This evaluation is split across 2 data tracks: a 10-minute track and 1-hour track, which corresponds to the amount of labeled data used to finetune the model per language. Within each track is several training settings. The monolingual setting tests the model on monolingual ASR for 13 languages separately. The multilingual setting evaluates the model on language identification (LID), multilingual ASR, and joint LID+ASR on all 143 languages.
While ML-SUPERB had the highest language coverage yet of any speech benchmark, it is far from the ~8000 languages spoken around the world. Further growing this coverage, however, is no simple task. Paired speech/text data is expensive to obtain, particularly for languages with smaller populations. Data quality is also a concern, as the findings that can be gleamed from the benchmark rely upon the reliability of its data sources. Given these challenges, how can we extend speech technologies to new languages? We believed that the solution laid in community-driven efforts, integrating the work of researchers across the globe. The ML-SUPERB Challenge was thus born, inviting researchers to contribute corpora for new languages and design new methods for multilingual speech processing.
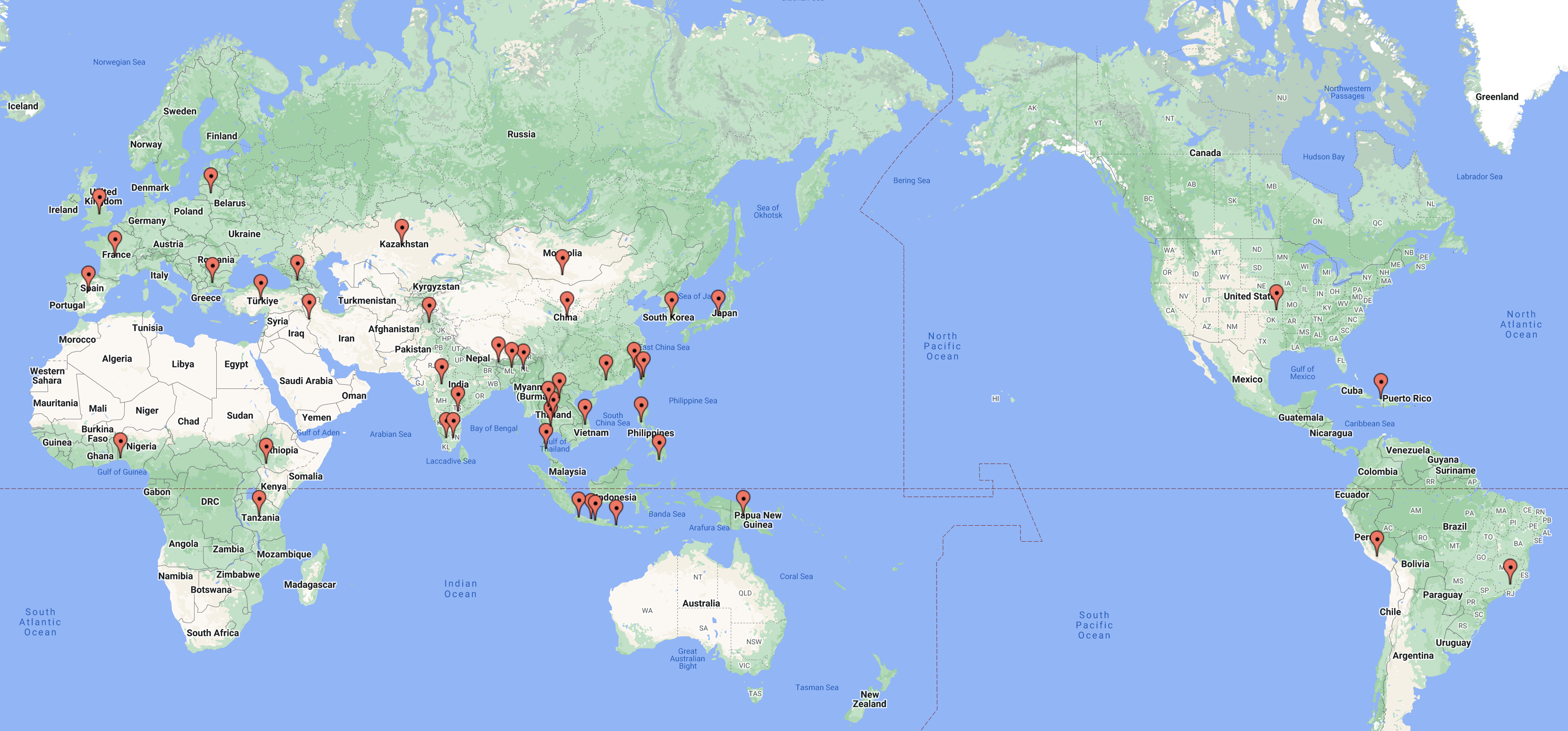
In total, we received 54 languages submitted to the challenge, increasing the number of unique languages in the benchmark to 154. A few of the new languages added include Quechua and Taiwanese Hokkien. While some submitted languages overlapped with those originally in the benchmark, they extended the corpora to new coversational, dialectal, and recording scenarios. We used these submissions to construct a hidden set for ML-SUPERB, which was used to further evaluate new and existing self-supervised models. Importantly, the new hidden set mostly consists of conversational speech, whereas the existing public set was mostly read speech. We found that model performance could vary significantly between the two regimes, showing that further work is necessary to build truly universal speech representations.
What’s Next?
- We are in the process of releasing the YODAS dataset, which is its own challenge due to the size (100+TB!)
- Our next generation of models will combine all of these works togther! We plan to combine integrate SSL pre-training into OWSM, and then train it on YODAS + more data.
- ML-SUPERB will be extended to even more languages and tasks.